The answer is both yes and no. Machine translation (MT) has become very powerful. You can use it to get a rough draft of foreign text. However, that rough draft may need to be retranslated or to undergo human post-editing to become accurate. Remember that translations are supposed to do for target-language readers what the source-language text did for its original readers.
More often, machine translation is used to gain some understanding when coming across unknown text. I use MT to help me track down unfamiliar terms, which I then go and validate in original sources—or discard. Lately, I also find myself “MT reading” articles in languages I do not know. But I would not publish the machine translation versions for my readers without careful postediting or a brand-new translation (and proper permission, of course)!
Postediting is the human editing of machine-generated translations to achieve an acceptable final draft. Why do I mention brand-new translations? Because, as editing involves corrections, adaptations, and other changes aimed at producing a consistent, accurate, and complete text, it is sometimes easier to start from scratch than to fix a problematic or unnatural text.
DeepL and the Machine Translation World
Let’s look at a new player in the machine translation world, DeepL Translator. It’s a powerful competitor to Google Translate. In a press release in August 2018, the company stated that “[i]n blind tests pitting DeepL Translator against the competition, translators preferred DeepL’s results by a factor of 3:1.”
DeepL stands for “deep learning.” The company’s founder and CEO, Gereon Frahling, explains that their engine arranges the artificial neurons and their network connections differently so they can now “map natural language more comprehensively than any other neural network to date.”
He also points out that DeepL achieves record BLEU scores. BLEU is the Bilingual Evaluation Understudy, an algorithm that compares a candidate translation to one or more reference translations.
How does DeepL do this? Although DeepL has not shared details about the algorithms used, they claim that their strength comes from access to over a billion high-quality translations from Linguee, one the of the world’s largest databases of human translations, also started by Frahling together with Leonard Fink.
It’s true. We’ll see some examples. It does not mean they have reached a singularity point: the merging of human and artificial intelligence that would produce thinking machines.
Testing MT in Real Life
My students and colleagues know I love technology and embrace it even in the face of resistance. (Back in 2005, I advocated for, planned, and finally launched a Translation/Localization Management degree against a backdrop of much suspicion towards tools.) So, when I was presented with DeepL, off I went to run some tests of my own.
I plugged in different types of text, including marketing, medical, and literary, some Spanish and some English. For reference, I also ran the texts through Google Translate. Let’s look at some examples.
Text #1
This is a fairly mundane example, an article about real estate talking about prohibitive prices for elders and young families. The Spanish version from both engines literally says, “We are putting a price on elders and young families.” Not quite what you would want your readers to see, right?
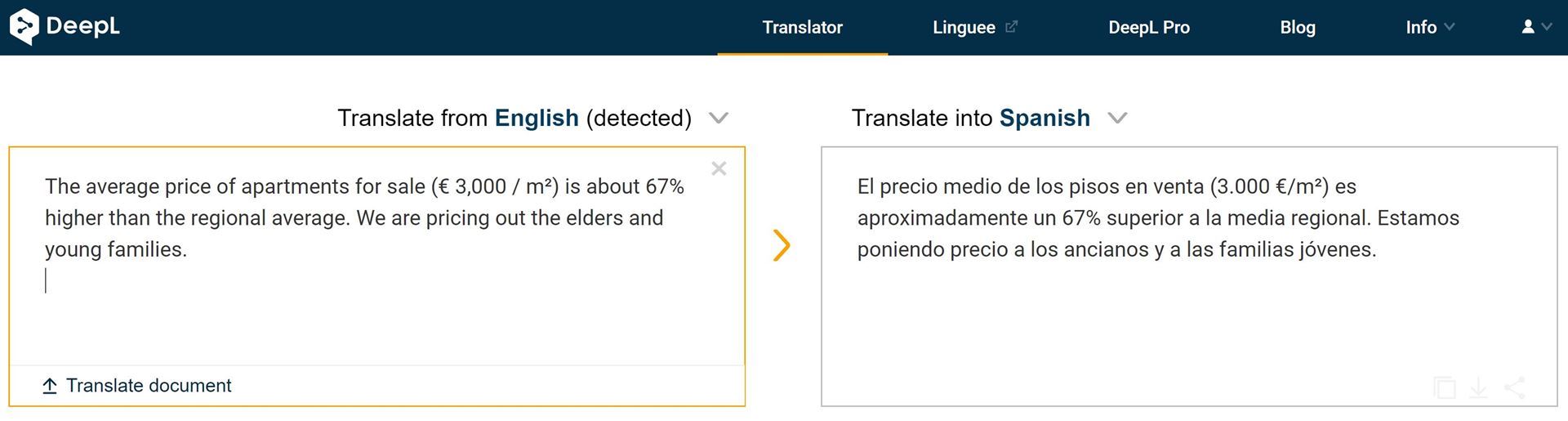
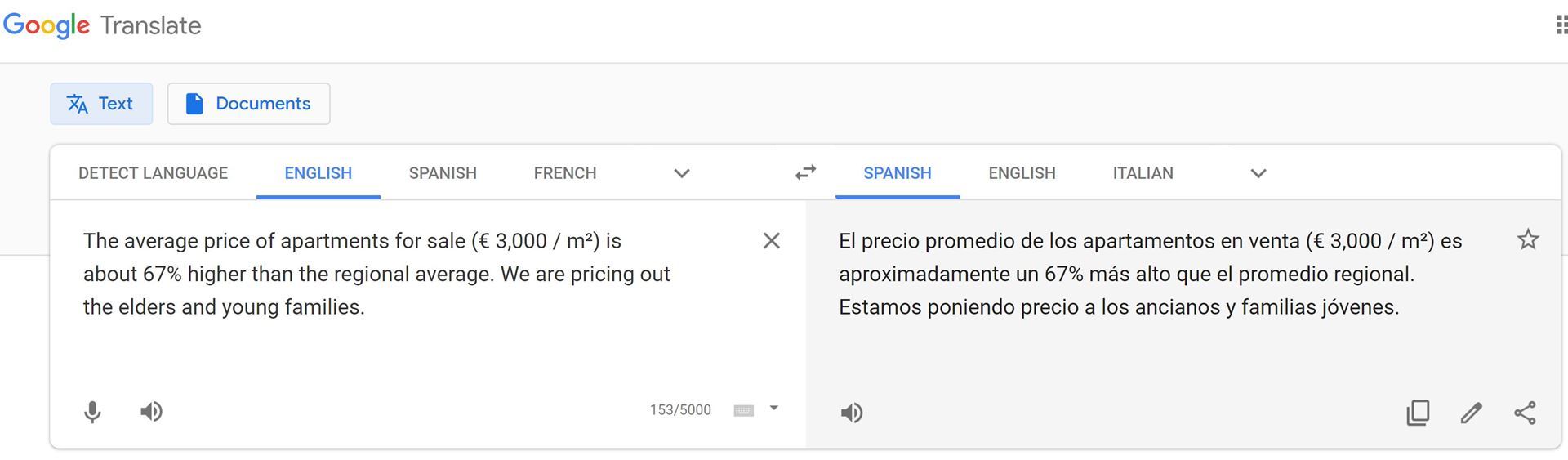
Text #2
This example is quite technical, from an installation manual, purportedly a perfect text for translation automation.
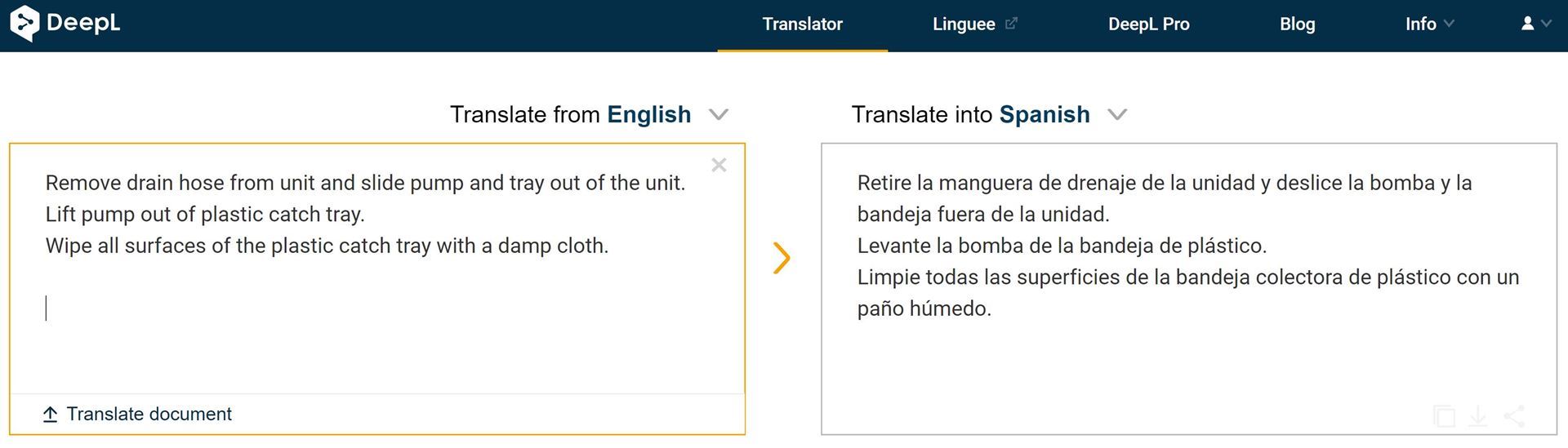

It is, for the most part, pretty straight forward. Except that in Spanish no one would instruct you to slide something in order to remove it, and much less to slide it outside of something (that sounds off even in English). They would simply instruct you to remove it. This is because manner is not routinely expressed in Spanish as it is in English. Google gets “lift pump out of plastic catch tray” right as “remove the pump the from plastic tray” while DeepL makes the same manner mistake from the first item, rendering it as “pull up the pump in the plastic tray,” which may or may not mean to separate pump and tray.
Text #3
It’s an excerpt from “The Library of Babel” by Jorge Luis Borges. Before you say, “it’s unfair, because it’s literature!” Let me say that, because it’s literature, at least parts of the text are likely quoted in the corpus (collection of texts) accessed by translation engines, so it may have a better chance that novel text. Although, in principle, DeepL will not simply spit out an existing translation that may have been used to train it, but assemble a new one for you.
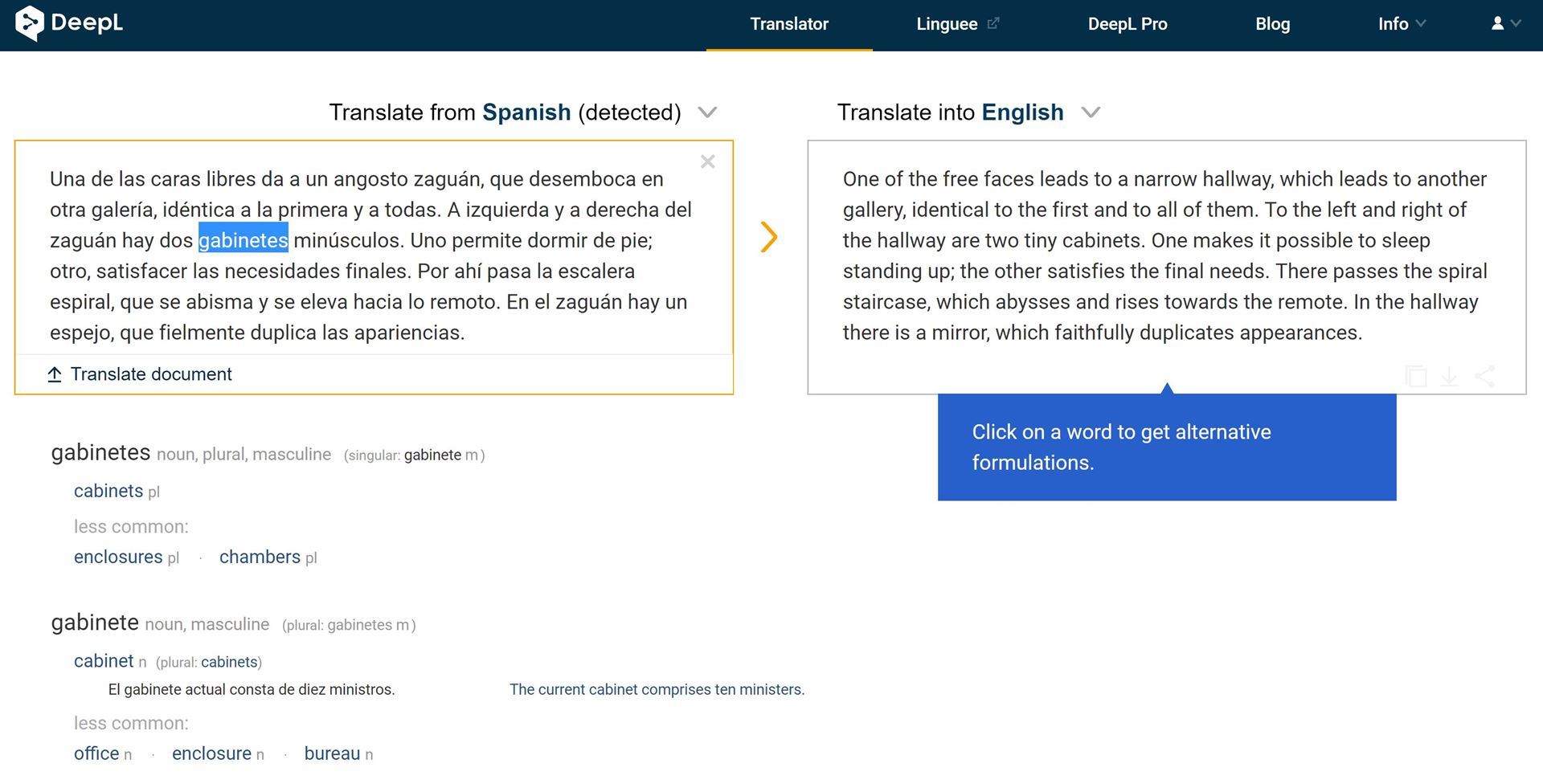
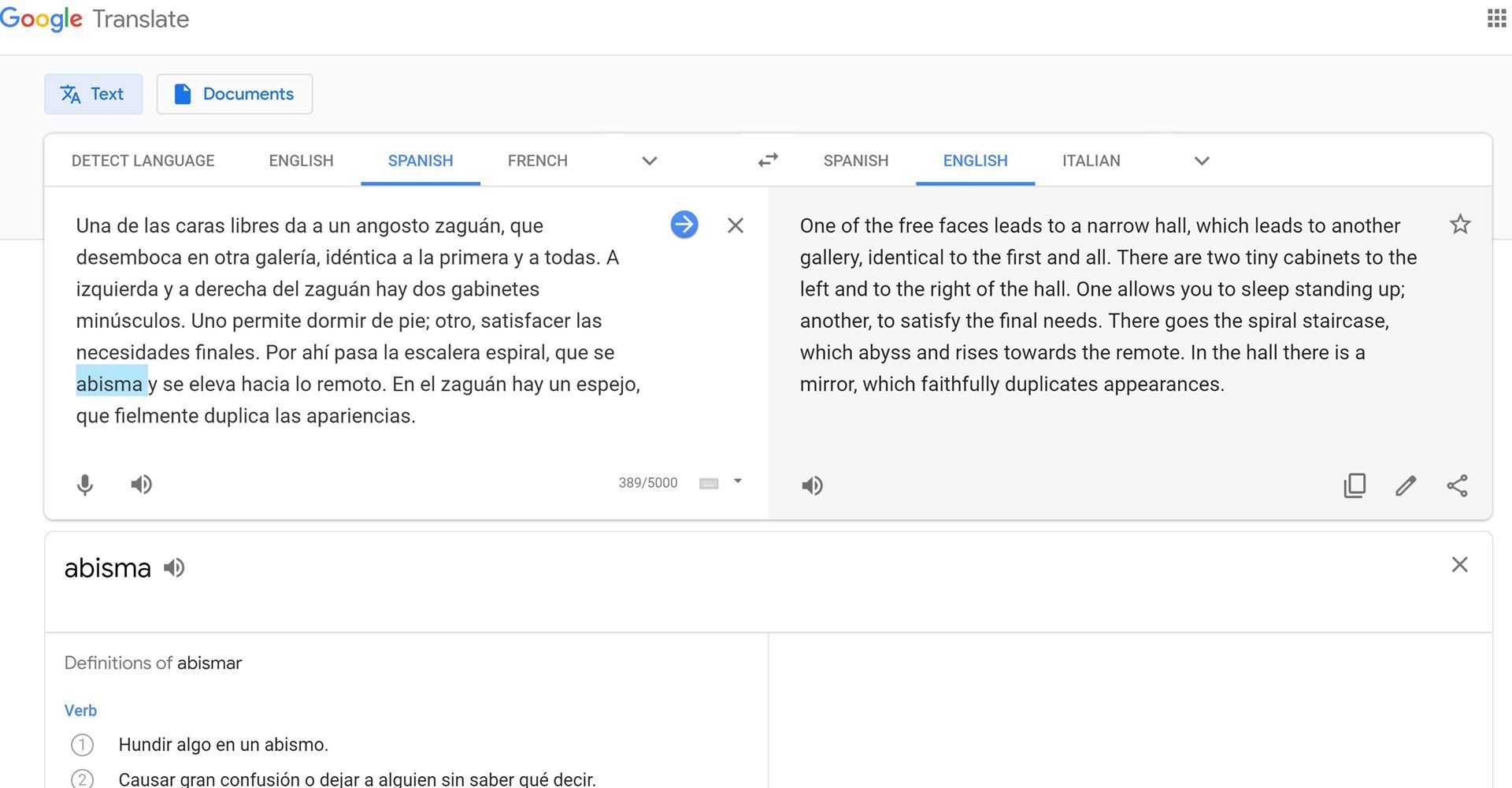
After reading the results, you can tell that both engines stumbled quite a bit. The noun “gabinete,” for instance, means “cubicle” rather than “cabinet,” and the words “abyss/es” and “rises” clumsily describe the spiral staircase’s endless upward and downward twisting. As you will see in the human translations quoted at the end, the staircase more aptly “winds upward and downward” or “sinks abysmally and soars.”
(In the human translations, adaptation, localization, and transcreation options are used to ring true to the intended reader, rather than for the sake of change.)
All in all, both engines got the gist of it, so maybe now you are interested in reading the whole story. That’s a huge accomplishment!
Now for some fine combing: DeepL got a bit more in meaning and form. Compare the gallery “identical to the first and to all of them” to Google’s “identical to the first and all.”
One nifty feature is the option to look up terms from the original text by simply clicking on them, as the example shows for “gabinete” in DeepL and “abisma” in Google. Unfortunately, it does not seem to work for every word: “abisma,” a form of the verb “abismar” yields no result in DeepL.
One big plus for DeepL Pro (in the for-fee service starting at about $5/month) is the promise of data confidentiality. The system promises to delete the texts fed to it immediately after you receive the translation.
Overall, I am liking DeepL very much. But, as you saw in this few examples of informal, technical, and creative text, the human mind grasps meaning at a level unrivalled by the machine (at least, for now).
So, by all means, use it to get the gist of text in an unknown language or even to kick start your translation or brain storm for terms and keywords. Just know that if you want or need your text to be read, understood, used, and appreciated by human readers, relying solely on the machine version can get you in trouble.
Questions or comments? Write to romina at language compass dot com.
----
Translations of the excerpt from The Library of Babel
One of the hexagon's free sides opens onto a narrow sort of vestibule, which in turn opens onto another gallery, identical to the first-identical in fact to all. To the left and right of the vestibule are two tiny compartments. One is for sleeping, upright; the other, for satisfying one's physical necessities. Through this space, too, there passes a spiral staircase, which winds upward and downward into the remotest distance. In the vestibule there is a mirror, which faithfully duplicates appearances.
Jorge Luis Borges, translated by James E. Irby
One of the free sides leads to a narrow hallway which opens onto another gallery, identical to the first and to all the rest. To the left and right of the hallway there are two very small closets. In the first, one may sleep standing up; in the other, satisfy one’s fecal necessities. Also through here passes a spiral stairway, which sinks abysmally and soars upwards to remote distances. In the hallway there is a mirror which faithfully duplicates all appearances.
Jorge Luis Borges, translated by Anthony Kerrigan
----
